Compute Optimization Features#
CV Parallel#
By tuning execution so that Cube and Vector compute can run in parallel across multiple streams, contention is reduced and compute efficiency improves.
Multi-instance#
In a single-instance scenario, tasks on the accelerator are executed serially. When multiple models coexist, later models must wait until the earlier model completes inference, which wastes hardware resources. Multi-instance optimization addresses this by running multiple model instances on a single device at the same time, improving overall service throughput.
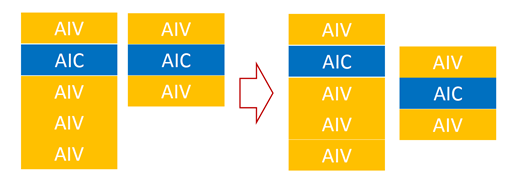
The figure below shows a two-instance example:
In case ①, the two models execute serially, so
task1must wait untiltask0completes. In case ②,task0andtask1run in parallel, improving total throughput.In case ③, compared with ②, the two models also reuse weights. This reduces additional memory demand and further improves throughput.
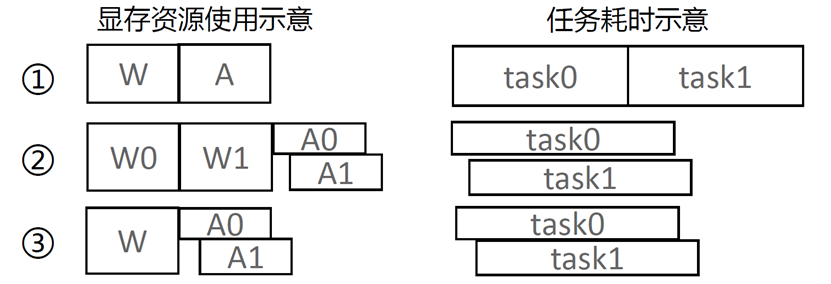
CFG fusion#
CFG (Classifier-Free Guidance) improves generation quality by combining positive-sample and negative-sample inference. In a conventional implementation, the positive and negative branches each run a full forward pass. Because most of the compute path is shared, this introduces a large amount of redundant work. CFG fusion concatenates the positive and negative samples so that operator calls and repeated compute are reduced, improving inference speed.
Operator fusion#
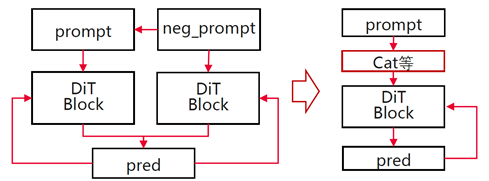
RoPE fused operator
RoPE (Rotary Position Embedding) fused operators inject position information through rotation and improve DiT efficiency on sequence-like data. The operator position is illustrated below:
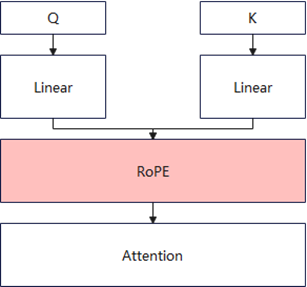
Rotary position encoding injects positional information into
qandkthrough a rotation matrix, so the attention computation can encode token position relationships. It is widely used across modern models and is an efficient positional encoding method.Rotational encoding encodes positional information directly into token embeddings so the model can capture relative position relationships without depending on absolute positions.
The rotation is applied independently per dimension, which helps the model capture positional information across feature dimensions.
No additional trainable parameters are required, so the method is computationally efficient.
In typical implementations, the original code calls
apply_rotary_embfrom therotary-embedding-torchpackage. When optimizing with MindIE SD, you can replace that call withrotary_position_embedding.Original code:
class Attention(nn.Module): def __init__(self, xxx): # omitted def forward(self, hidden_states, freqs_cis_img): # omitted # apply_rotary_emb is the original implementation query = apply_rotary_emb(query, freqs_cis_img)
Optimized version:
from mindiesd import rotary_position_embedding class Attention(nn.Module): def __init__(self, xxx): # omitted def forward(self, hidden_states, freqs_cis_img): # omitted cos, sin = freqs_cis_img cos, sin = cos.to(x.device), sin.to(x.device) query = rotary_position_embedding(query, cos, sin, rotated_mode="rotated_half", head_first=False, fused=True) key = rotary_position_embedding(key, cos, sin, rotated_mode="rotated_half", head_first=False, fused=True)
RMSNorm fused operator
RMSNorm (Root Mean Square Normalization) is a normalization method that avoids explicit mean computation and focuses on the root mean square of the input tensor, reducing compute overhead.
In these models, RMSNorm often appears in DiT blocks after the
q,k, andvlinear layers and before FA. The location is illustrated below: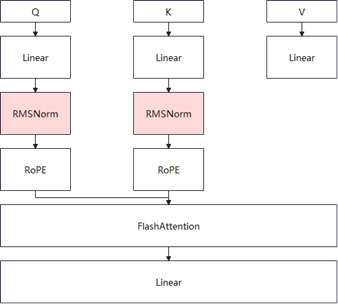
When optimizing with MindIE SD, use the
RMSNormimplementation directly:Original code:
norm_q = RMSNorm(dim_head, eps=eps) query = norm_q(query)
Optimized code:
from mindiesd import RMSNorm norm_q = RMSNorm(dim_head, eps=eps) query = norm_q(query)
attention_forwardMindIE SD lets you choose among low-level attention operator types such as PFA, FASCore, and LaserAttention. It can also search for the best-performing operator automatically, cache the auto-tuning result, and reuse the cached choice for repeated inputs of the same shape and type. This is mainly used in the attention modules inside DiT blocks, including both self-attention and cross-attention.
The auto-tuning flow has two stages:
During warm-up, when a new input format is observed for the first time, the runtime parses the input shape
(B, N, D, Q_Seqlen, K_Seqlen)and dtype, benchmarks candidate kernels, chooses the best operator and layout format such asBNSD,BSND, orBSH, caches the result, and executes inference.During steady-state execution, the runtime parses the input shape and dtype, looks up the cached optimal result, configures the attention backend, and runs inference. Only unseen shapes and dtypes trigger new online benchmarking.
Use the
attention_forwardinterface when optimizing with MindIE SD:Migrating from
torch.nn.functional.scaled_dot_product_attentionOriginal code:
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2) key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2) value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2) # the output of sdp = (batch, num_heads, seq_len, head_dim) hidden_states = F.scaled_dot_product_attention( query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False ) hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
Optimized code:
from mindiesd import attention_forward # q, k, v shape is (batch, seq_len, num_heads, head_dim) query = query.view(batch_size, -1, attn.heads, head_dim) key = key.view(batch_size, -1, attn.heads, head_dim) value = value.view(batch_size, -1, attn.heads, head_dim) # the input and output of attention_forward are (batch, seq_len, num_heads, head_dim) hidden_states = attention_forward(query, key, value, attn_mask=attention_mask) hidden_states = hidden_states.reshape(batch_size, -1, attn.heads * head_dim)
Migrating from
flash_attention.flash_attn_funcOriginal code:
q = torch.randn(batch_size, seqlen_q, nheads, d, device=device, dtype=dtype) k = torch.randn(batch_size, seqlen_k, nheads, d, device=device, dtype=dtype) v = torch.randn(batch_size, seqlen_k, nheads, d, device=device, dtype=dtype) out = flash_attention.flash_attn_func(q, k, v)
Optimized code:
from mindiesd import attention_forward q = torch.randn(batch_size, seqlen_q, nheads, d, device=device, dtype=dtype) k = torch.randn(batch_size, seqlen_k, nheads, d, device=device, dtype=dtype) v = torch.randn(batch_size, seqlen_k, nheads, d, device=device, dtype=dtype) out = attention_forward(q, k, v)
Note
attention_forwardexpects input tensors in(batch, seq_len, num_heads, head_dim)format and returns the same format.attention_forwardprovides forward inference only and does not provide backward gradients, so migration should remove dropout and set input tensor gradients toFalse.
Migrating from
flash_attn.flash_attn_varlen_funcwithcausal=FalseOriginal code:
out = flash_attn_varlen_func(q, k, v, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k, dropout_p=0.0, softmax_scale=None, causal=False)
Optimized code:
from mindiesd import attention_forward_varlen out = attention_forward_varlen(q, k, v, cu_seqlens_q, cu_seqlens_k, dropout_p=0.0, softmax_scale=None, causal=False)
Migrating from
flash_attn.flash_attn_varlen_funcwithcausal=TrueOriginal code:
out = flash_attn_varlen_func(q, k, v, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k, dropout_p=0.0, softmax_scale=None, causal=True)
Optimized code:
from mindiesd import attention_forward_varlen out = attention_forward_varlen(q, k, v, cu_seqlens_q, cu_seqlens_k, dropout_p=0.0, softmax_scale=None, causal=True)