Graphics Memory Optimization Features#
Tensor Parallel#
Refer to Tensor Parallel in the multi-card parallelism guide.
Memory sharing#
Core problem
In multi-instance scenarios, multiple models may use the same weights on a single NPU device, as shown below. Graphics memory sharing can reduce the overall footprint in that case.
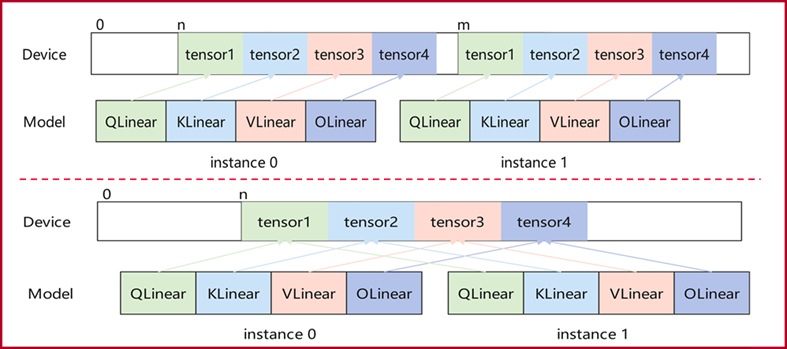
Theoretical basis
Different tensors can be built from the same physical NPU address and offset, allowing them to access the same memory region.
Design idea
A memory manager shared across processes manages the underlying memory, and each process reuses memory allocated by that shared manager.
Implementation flow
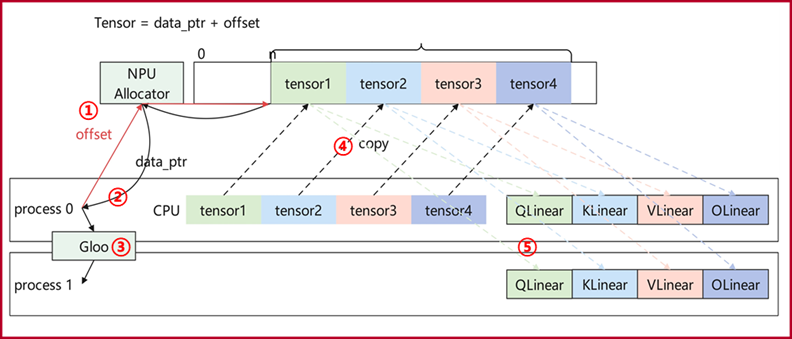
Process 0 calculates the required memory size and offset, then allocates memory through an inter-process shared NPU allocator.
The NPU allocator returns the physical address
data_ptrto process 0.Process 0 sends
data_ptrto process 1 through inter-process communication.Process 0 copies the CPU memory to the real NPU physical address.
Process 0 and process 1 both construct tensors from
data_ptrand the matching offset.
Asynchronous offload#
Background
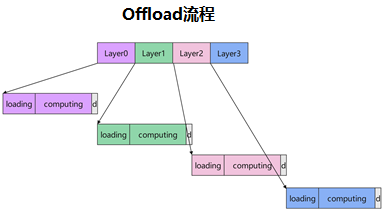
In synchronous offload mode, the accelerator stops after finishing one layer and waits while the next layer’s weights are moved from CPU memory to the accelerator. That leaves the device idle for a large portion of time and lowers utilization.
Optimization method
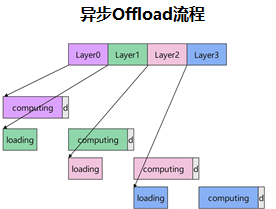
Asynchronous offload is a classic technique that trades time for space, or more precisely, inference speed for graphics memory capacity.
Its core idea is to overlap compute and weight transfer with an asynchronous pipeline. While the device computes one layer, the next layer’s weights are already being loaded. By the time the current layer finishes, the next layer’s weights are ready, so transfer time is hidden behind compute time and end-to-end latency is reduced.
The figures below show the standard offload flow and the asynchronous offload flow:
Quantization#
Refer to Linear Quantization in the lightweight algorithm guide.